
在Jflex如何比较好的识别字符
在Jflex如何比较好的识别字符串
前言
本文专注于解决在梅努斯国际工程学院中的CS310FZ编译原理这节课的某一次实验
在Lab4中,我们被要求写flex文件以识别:
字符串文字——由双引号括起来的字符序列。您可以假设包含的字符串不包含任何引号或其他可转义字符
因此本文将基于这个目标进行任务的完成————如果您是学习研究词法编辑器而看到了本文,建议阅读Jflex手册的第3-4章,作者的思路十分清晰
储备
上官方手册:https://www.jflex.de/manual.html#content
如果您想比较好的明白这篇文章的内容,您可以先完整阅读以下部分:
1.A simple Example: How to work with JFlex
2.Lexical Specifications
如果您懒得阅读,请直接看下面的部分:
完成该任务的知识
flex文件的组成
JFlex 的词法规范文件由三个部分组成,由以 %% 开头的单行分隔,简而言之就是这样:
1 | A.用户代码部分:这部分会写在生成的Java文件的类的最开头,一般而言会写一些ipmort在这 |
JFlex中的Lexical rules的语法
即在C部分的语法,这部分语法可以被概括为:
1 | 识别的东西 + {额外的Java代码} |
举个例子,我们写下
1 | "float" {return new Token (Token.FLOAT_WORD, yytext());} |
在生成的Java文件中就会有如下的代码:
1 | case 36: |
其中怎么到这个case,就是你写的“识别的东西”决定的,一般就是写一个正则表达式
简单来说,这部分的语法:前面的负责找东西,大括号里面的可以指定找到之后干啥
JFlex中的状态
JFlex中是有状态来进行匹配的,状态用<XXXXX>来标识
默认的状态是<YYINITIAL>
书接上文,如果我们在Lexical rules部分写下:
1 | <AAAA> rex + {额外的Java代码} |
就代表只有在A状态下,才进行rex的识别匹配,识别匹配成功了才能执行大括号里面的任务
YYINITIAL是隐含的默认状态,其实可以省略
用手册的例子说明: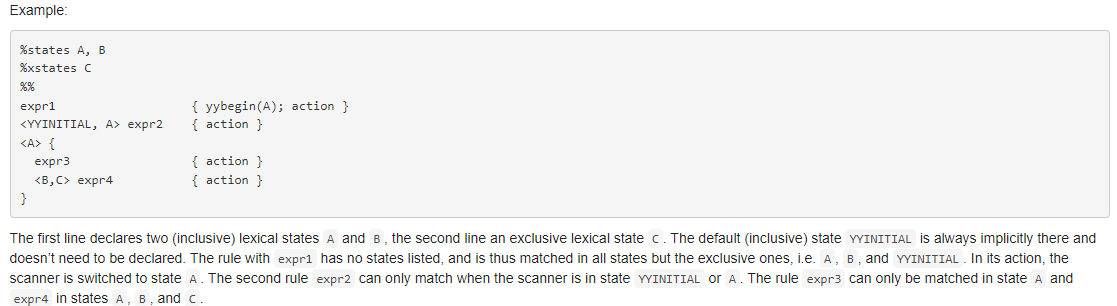
1.默认情况(YYINITIAL)会识别expr1,然后识别成功后,因为代码yybegin(A),会让Jflex进入到A状态
2.在YYINITIAL和A状态下,如果识别到了expr2,采取action(手册里很喜欢把这部分叫action)
3.在A状态下,如果识别到expr3则进入对应action,而状态也可以内联,这里就不多说了
状态的声明
一定要在B.设置和声明这部分声明你的状态
使用Jflex的语法%state 名字
主要,用state和xstate声明是不一样的。手册里有相关介绍,但是这里我们用不上
开始干活吧!
0.手册是怎么实现的
手册利用了一个包import java_cup.runtime.*;实现,但是我们不想导包(而且你提交的时候老师助教也不一定有这个包)
所以我们不这么干————有探究精神的话可以导并且参考手册的A simple Example: How to work with JFlex部分
1.存储String
我们用一个StringBuffer来存储字符串的内容,这部分要先写在B.设置和声明里面
1 | %{ |
2.声明STRING状态
同样的,在B.设置和声明里面写入:
1 | %state STRING |
3.在Lexical rules部分写下相关逻辑
在C.Lexical rules中写下:
1 | <YYINITIAL>\" { string.setLength(0); yybegin(STRING); } |
这个语句的意思是,在默认状态下,如果检测到了双引号,那么:
1.将StrinBuffer清空
2.进入STRING状态
然后我们继续写:
1 | <STRING> { |
这个就是Jflex进入STRING后会识别并采用的操作,后面几行不重要,意思就是各种转义的处理
重要的是[^\n\r\"\\]+ { return new Token (Token.STRING, yytext());}
它意味着,如果检测到字符串结束,就执行你自定义的action,并且开始下一次识别
FINAL
至此大功告成
当然,这是我晚上做实验的时候(好不容易)模仿原定思路修改的,也许会有bug,请多包涵
另外,关于注释的识别,也可以按照这个思路完成




