
cs130数据库:PgSql模块(下)
pgSQL 3.1
主外键
主键外键的概念
主键是定义的,一个数据字段唯一的标识符,在表中,不会存在相同的主键
创建主键
我们可以直接增加primary key约束来创建主键
我们还可以使用constraint语法来创建主键:constraint <主键名称> primary key(创建主键的字段的名称)
创建外键
constraint <外键名称> foreign key(创建外键的字段) references <参考的表>(<参考的字段>)
比如constraint fk_em3_dept foreign key(deptID) references dept(id)
在这个表中,将字段deptID设置为外键,它引用至dept这张表的id字段
外键关联/引用的字段,一定是另外一张表的主键
主键约束和外键约束的作用
主键约束:
唯一标识一条记录
提高数据的检索效率
外键约束:
保证数据的完整性
提高数据的检索效率
非空、唯一、默认值约束
非空 NOT NULL
不能向对应字段插入null值
唯一 UNIQUE
是对应字段不能出现重复的数据
同样是唯一的标识,主键约束是不能为空的,而唯一约束是可以让字段为空的,而且null不算做重复;另外,在一个表中,我们只能指定一个主键,但可以创建多个唯一约束
默认值 default<数据>
在某一数据为空null的情况下,用默认值代替
pgSQL 4
HAVING 运算符
LIMIT 运算符
表约束
HAVING 操作符
当我们想要获得”在某种条件之下的组”的时候,我们利用HAVING操作符
这件事要从Group By 说起,那么我们先假设这么一张表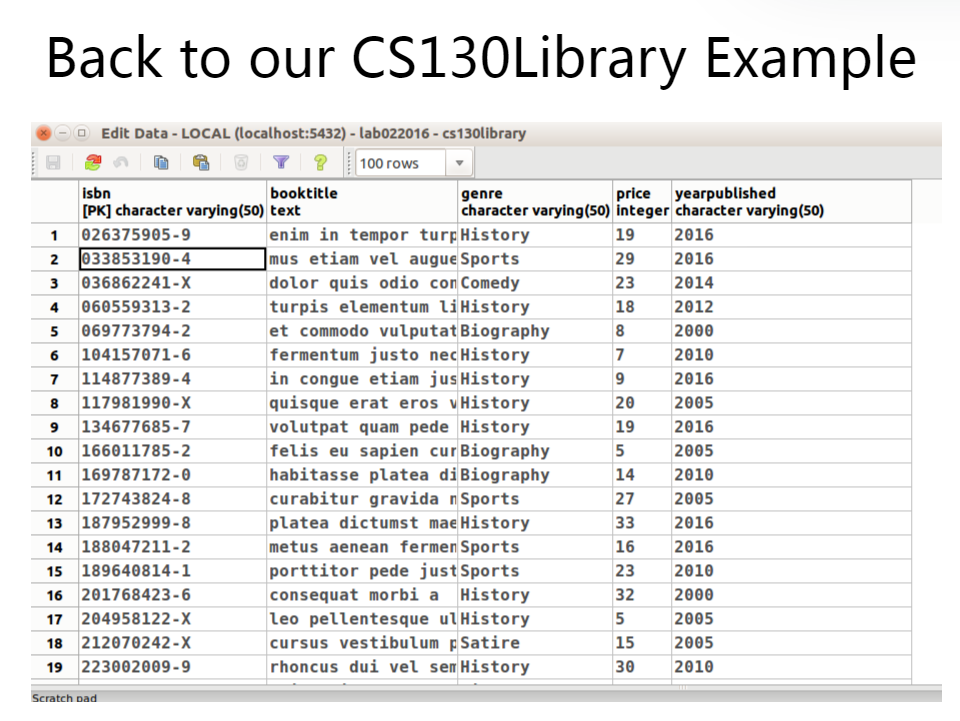
我们想要书店里每种类型的书有多少,于是我们利用命令改表并分组
1 | SELECT Genre,count(*) as NumberPerGenre |
然后我们可以得到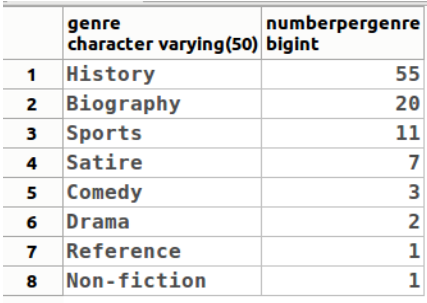
现在我们想仅查看类型大于5的书,那么如果我们尝试使用WHERE系列命令,会得到一个报错
此时就是使用HAVING的时候了
1 | SELECT Genre,count(*) as NumberPerGenre |
HAING子句类似于WHERE子句,但是它仅被用于作为一个整体的组(也就是结果集中代表组的行),而WHERE子句适用于单行
查询中可以同时包含HAVING和WHERE子句
其中WHERE子句会先被运用于表的各行,再对满足WHERE子句的行进行分组
我们看一个例子: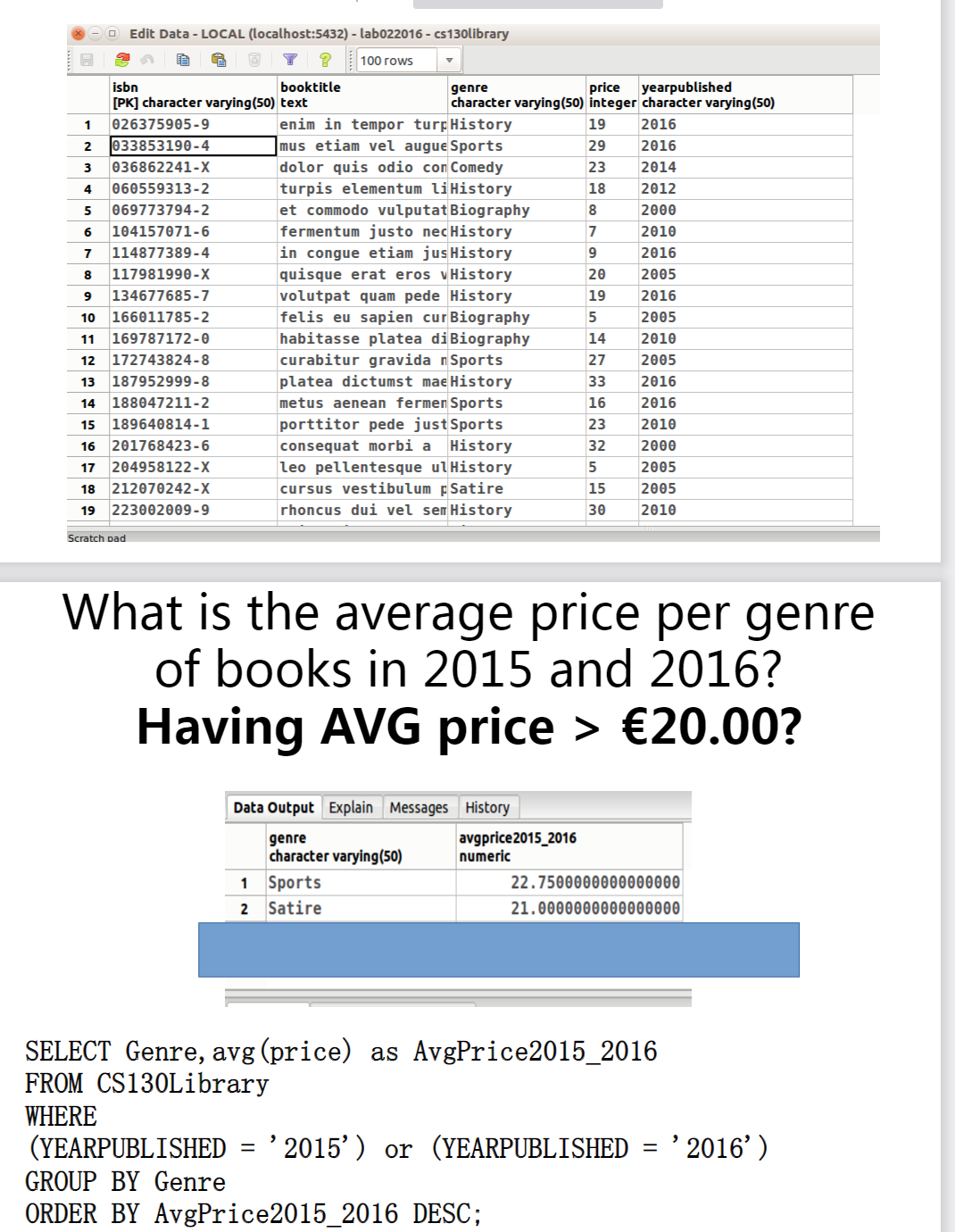
1 | SELECT Genre,avg(price) as AvgPrice2015_2016 |
HAVING 和 WHERE
– WHERE 在计算组和聚合之前选择输入行(因此,它控制哪些行进入聚合计算)
– HAVING 在计算组和聚合之后选择组行
LIMIT操作符
LIMIT 操作符限制输出 结果集ResultSet 中显示的行数
它不像是另外一种WHERE,而是只控制“如何在结果集中显示行”这件事
例子:
LIMIT 和 ORDER BY
使用LIMIT时,我们使用ORDER BY 子句将结果约束为应该唯一的顺序,这是十分重要的。否则,可以会导致查询的行不可预测地执行LIMIT
您可能会要求从第十行到第二十行,但是从第十行到第二十行的顺序是什么?顺序未知,除非您指定 ORDER BY
CONSTRAINT操作
实际上,我们之前已经使用过了CONSTRAINT了,比如NOT NULL和PRIMARY KEY
PostgreSQL 不会泄露导致检查约束失败的一个或多个值的详细信息——它只是告诉您CONSTRAINT失败
CHECK CONSTRAINT
一个检查约束CHECK CONSTRAINT是最通用的约束类型
它允许您指定某个列中的值必须满足布尔(结果为真)表达式
CHECK 约束意味着如果 INSERT 语句或 UPDATE 语句没有通过 CHECK 约束,它们将不会被执行
Date and Time Constraints
NOW()函数:
1.允许我们访问精确的当前的日期和时间而作为TIMESTAMP
2.它是一个函数,它可以用于任何有效的语句,包括但不仅限于(SELECT,UPDATE,DELETE,INSERT)
3.不接受任何参数和引用
pgSQL 5
表作为SQL中的集合
Tables as Sets in SQL
总览
ALL
DISTINCT
UNION
EXCEPT
INTERSECT
重复组、ALL和DISTINCT
一般而言,SQL并不会自动删除重复的数据:一是因为性能消耗,二是因为可能用户需要重复的数据
当我们想要删除重复部分的时候,我们使用DISTINCT关键字
在SELECT子句中使用DISTINCT可以让结果保留不同的元组,而对应的,使用ALL关键字则不会
另外,在不指定任何关键字的时候,等同于我们使用了SELECT ALL
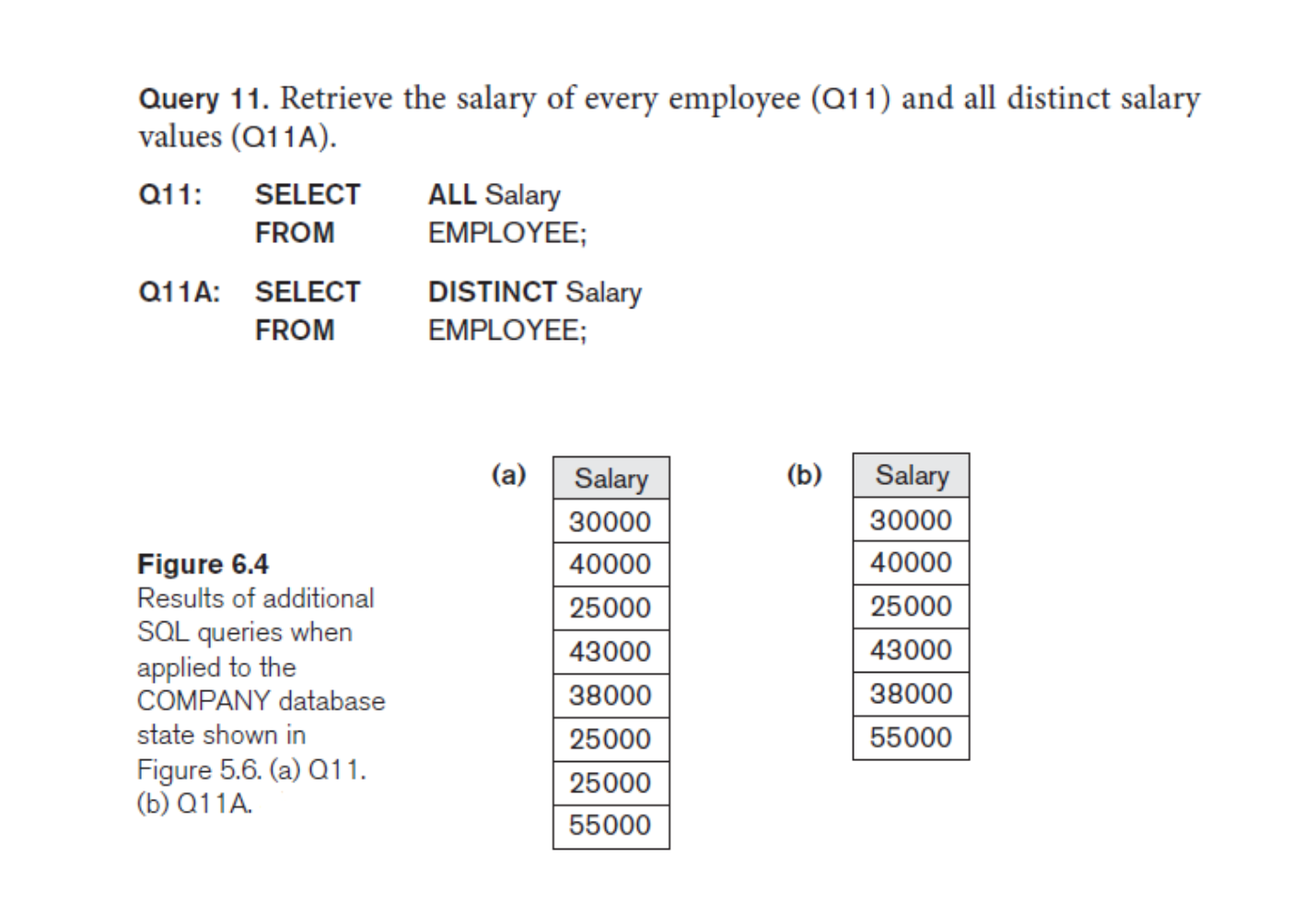
注意,如果同时搜索两个部分,那么只有两个部分都完全一样的数据元组会被删除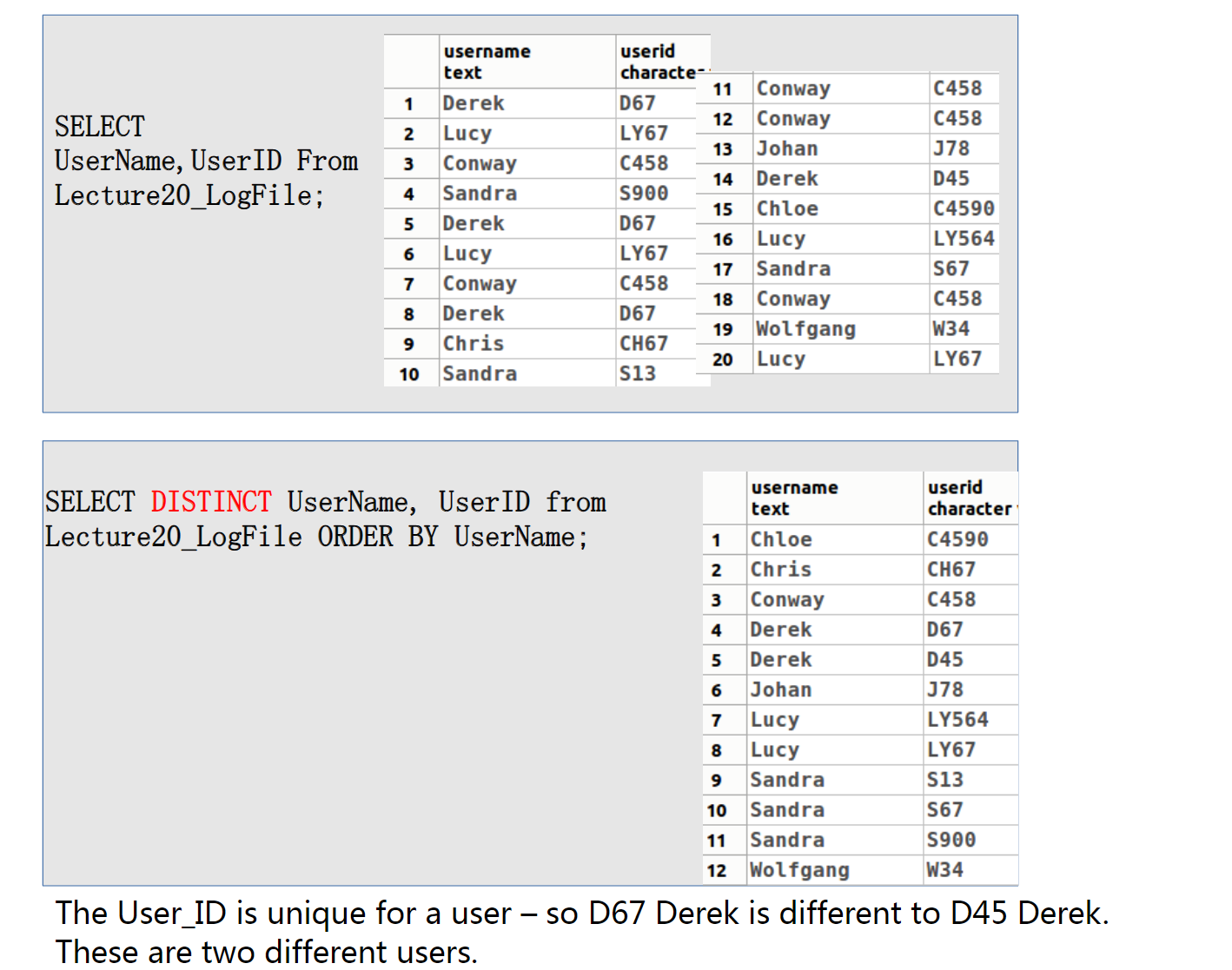
Set 操作
SQL中提供了很多合并集的操作,后跟 XXX ALL 关键字,它们的结果是多集,并且重复项会被按要求处理
常见的有:
UNION ALL :直接合并不处理
EXCEPT ALL:对A而言,插入其中B没有的部分(差运算)
INTERSECT ALL:以A为基本插入B,并且只保留二者相同的部分
UNION (ALL)
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行
EXCEPT(ALL)
EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行
INTERSECTALL(ALL)
INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行

psSQL 6
查询操作合集
总览
当我们进行查询的时候,我们可以大致把SELECT规划为下面的部分:

这些部分在前面的md都提到了,可以去看对应的部分
简单基础查询
select <展示字段,*为全部> from <表>
我们可以在字段前面指定表的名称,来保证一些字段是来自指定的表
比如select emp1.name form emp1
打表名的全名很麻烦,因此可以增加as操作符来简化select e.name,e.id,e.hireDate form emp1 as e ;
另外,as关键字不算必须的,也就是说是可以删掉的。不过为了可读性,还是尽量保存它吧
为字段取别名
意义不大但是还是记录一下,在字段的后面直接跟上别名即可select e.name as a , e.id as b
另外,此时显示出来的结果就是别名了
(这里的as也是可以省略的)
单表指定条件查询
select XXX from abc WHERE<条件>
IN:一个内容是否落在一个集合中,比如 1 in (2,1,3,4)
(可以使用 not in 来取反)
BETWEEN:一个内容是否落在一个区间当中,2 between 2 and 4,两边都是闭区间,也可以not 取反
LIKE:模糊匹配,具体看相关的MD和PDF笔记
is null:查询某个字段中为空值的内容,is nor null``则是取反 select a from b where b is null```
别用=,在数据库中,null是和任何值都是不相等的
ORDER BY 字段 asc/desc:排序,asc是升序,desc是降序
(默认是asc)
order by 可以指定多个字段,先按前面的字段排序,在前面字段的排序相等的情况下,执行后面的进行排序 select a from b order by point asc , salary desc
先按照point升序排序,再按照salary进行降序排序
在排序的时候,有时null会按最大值被处理。此时再在后面加上nulls first关键字则可以把null提到最前
1 |
|
SELEECT e_no,e_name,e_job,d_no,d_name,d_location
FROM employee,dept
WHERE dept_no = d_no
1 | 从两张表格中检索数据,并且根据一次等职比较连接 |
SELECT e_no,e_name,dept__no,d_no,d_name,d_location
FROM employee left join dept on dept_no = d_no;
1 | 这就是左连接,它的意思是**返回左表中所有查询的内容**,包括匹配的,以及不匹配的(null) |
select * from employee
Where exists
(select d_no from dept where d_name = ‘开发部’)
1 | 对于Exists子查询,先进行子查询,如果子查询得到了结果,则相当于给予exists一个true |
select * from employee where dept_no in
(select d_no from dept where d_name = ‘开发部’)
1 |
|
select a form b1 where
union all
select a from b2 where
```
二者的字段数应该是相同的,而如果两张表的字段有差,则可以使用null来代替缺少的字段




